智谱发布 GLM-5V-Turbo,把视觉理解接进编程模型
2026 年 4 月 2 日,新浪科技援引智谱公开信息报道称,智谱发布 GLM-5V-Turbo,定位原生多模态 Coding 基座模型。和只处理文本的编程模型相比,它把视觉理解直接接进了同一条推理链路,设计稿、网页截图和图表都可以直接进入生成过程。
这类能力对应的不是普通补全场景,而是先看懂界面再决定怎么改代码的任务。前端还原、GUI 操作和视觉代理,都更依赖模型先理解屏幕状态,再规划后续动作。
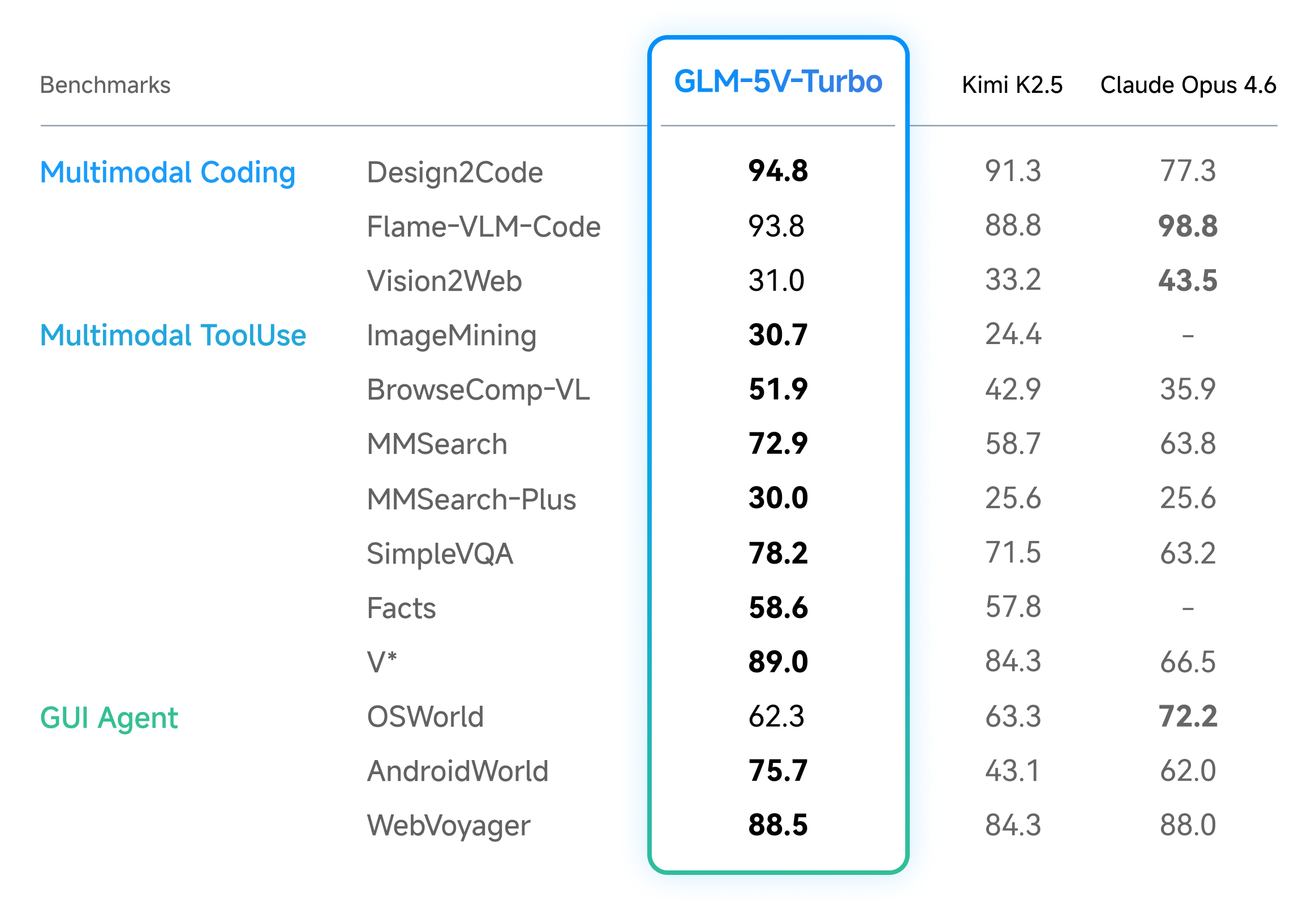
按公开信息,这款模型原生处理文本、图片和视频输入,在多模态 Coding 与 Agent 相关基准上保持了较强表现,同时没有把纯文本编程能力单独拆出去。另一个被反复提到的点,是它和 OpenClaw 的适配,目标是让 Agent 先看懂界面,再继续执行。
视觉理解和稳定执行之间仍然隔着很长一段距离,但模型层开始把“看图”和“写代码”放进同一套入口,编程代理后面会越来越多地面对真实界面而不是纯文本仓库。